Train and Inference¶
| 題名: | 訓練(train)と推論(inference)の解説 |
|---|---|
| 著者: | 柏木 明博 |
| 作成日: | 2017年7月24日 |
訓練(train)¶
これまで、Forwardpropagation、Backpropagation、GPUの使い方を解説しましたが、 ここでは、それらを組み合わせて訓練(train)と推論(inference)を行います。訓練 がBackpropagation、推論がForwardpropagationとなりますが、推論した結果と正し 答えとの誤差を学習するため、推論 –> 訓練の順番で処理を行います。
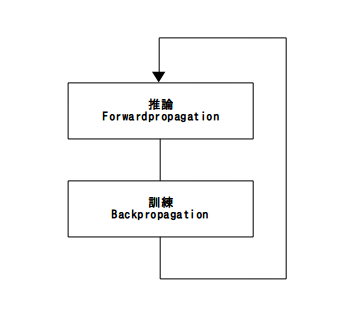
図1.訓練(train)と推論(inference)
フローチャート¶
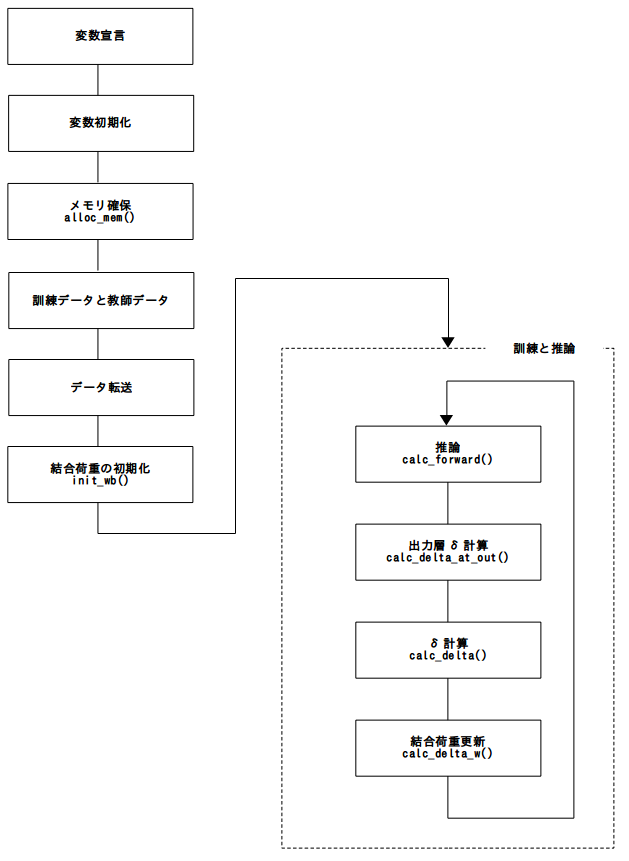
図2.全体の流れ
変数宣言¶
まずは、変数宣言部分です。入力層、中間層、出力層の3層のバックプロパゲーショ ンとなるため、z,b,w,d,db、各3要素づつ確保しています。また、入力層は2ユニット、 中間層は7ユニット、出力層は2ユニットとなります。
LIST 1. 変数宣言
int main(int argc, char *argv[]){
// Error of cuda
cudaError_t err;
// Size of data
long size;
// Number of phase this network
long l_num;
// Number of z at each phase
long z_num[3];
// Number of b at each phase
long b_num[3];
// Number of w at each phase
long w_num[3];
// Number of d at each phase
long d_num[3];
// Number of db at each phase
long db_num[3];
// Memory pointer at cpu side
long train_num;
// Number of train row
long teach_num;
// Number of teach row
void *mem_cpu;
// Memory pointer at gpu side
void *mem_dev;
// Memory pointer at cpu side for long
void *train_cpu;
// Memory pointer for train for cpu
void *train_dev;
// Memory pointer for train for dev
double *train_p;
// Pointer for access to train data
void *teach_cpu;
// Memory pointer for teach for cpu
void *teach_dev;
// Memory pointer for teach for dev
double *teach_p;
// Pointer for access to teach data
long uniti;
// Number of unit j
long unitj;
// Number of phases
long cnt;
// Number of counter
変数初期化¶
次に、変数の初期化を行います。変数の意味は、コメントの通りですが各層における ユニットの数を設定しています。l_numは、層数です。今回は、排他的論理和(XOR)を 学習されるため、train_numは、2[入力]×4[状態]=8以上を指定します。teach_numも 同様に、2[出力]×4[状態]=8以上を指定します。
LIST 2. 変数初期化
l_num = 3;
// Number of z value at phase 0
z_num[0] = 2;
// Number of b value at phase 0
b_num[0] = 0;
// Number of w value at phase 0
w_num[0] = 0;
// Number of d value at phase 0
d_num[0] = 0;
// Number of d value at phase 0
db_num[0] = 0;
// Number of z value at phase 1
z_num[1] = 7;
// Number of b value at phase 1
b_num[1] = 7;
// Number of w value at phase 1
w_num[1] = z_num[0] * z_num[1];
// Number of d value at phase 1
d_num[1] = 7;
// Number of d value at phase 1
db_num[1] = 7;
// Number of z value at phase 2
z_num[2] = 2;
// Number of b value at phase 2
b_num[2] = 2;
// Number of w value at phase 2
w_num[2] = z_num[1] * z_num[2];
// Number of d value at phase 2
d_num[2] = 2;
// Number of d value at phase 2
db_num[2] = 2;
// Init pointer for memory
mem_cpu = NULL;
mem_dev = NULL;
train_cpu = NULL;
train_dev = NULL;
train_num = 10;
teach_cpu = NULL;
teach_dev = NULL;
teach_num = 10;
メモリの確保¶
「汎用GPUにおける結合荷重及び関連値の確保と保持」で解説している通り、最初に ホスト(CPU)側とデバイス(GPU)側双方にメモリを確保する関数を作成し、関数名を alloc_mem()とします。引数は、変数宣言(LIST 1)と変数初期化(LIST 2)に挙げられ ているもので、以下の通りです。
LIST 3. メモリの確保
// Allocate liner memory
size = alloc_mem(
// number of phases
l_num,
// number of phases for z
z_num,
// pointer for z array
b_num,
// pointer for b array
w_num,
// pointer for w array
d_num,
// pointer for d array
db_num,
// pointer for db array
&mem_cpu,
// pointer for liner memory at cpu side
&mem_dev,
// pointer for liner memory at gpu side
&train_cpu,
// pointer for train data
&train_dev,
// pointer for teach data
train_num,
// number of train row
&teach_cpu,
// pointer for train data
&teach_dev,
// pointer for teach data
teach_num
// number of teach row
);
if( size < 0 ){
// error terminate
printf("Error in alloc_mem()\n");
exit(0);
}
訓練データと教師データ¶
ここでは、パーセプトロンでは対応できない非線形データである排他的論理和の学習 を行うため、train_cpu配列に入力値、teach_cpu配列に出力値を設定します。排他的 論理和(XOR)については、別途、調べてご確認ください。
LIST 4. 排他的論理和(XOR)の入力値(train)と出力値(teach)の設定
train_p = (double *)train_cpu;
teach_p = (double *)teach_cpu;
// Set train data
train_p[0] = 0.0;
train_p[1] = 0.0;
train_p[2] = 1.0;
train_p[3] = 0.0;
train_p[4] = 0.0;
train_p[5] = 1.0;
train_p[6] = 1.0;
train_p[7] = 1.0;
// Set teach data
teach_p[0] = 0.0;
teach_p[1] = 1.0;
teach_p[2] = 1.0;
teach_p[3] = 0.0;
teach_p[4] = 1.0;
teach_p[5] = 0.0;
teach_p[6] = 0.0;
teach_p[7] = 1.0;
データの転送¶
ホスト(CPU)側メモリのデータを、デバイス(GPU)側メモリへ転送します。先述の通り メモリは線形化した状態で確保しているため、訓練用データ(train_cpu)、教師用デ ータ(teach_cpu)、作業用データ(mem_cpu)の3ブロックをそれぞれ転送するだけです。
LIST 5. データの転送
err = cudaMemcpy(
train_dev,
train_cpu,
sizeof(double) * z_num[0] * train_num,
cudaMemcpyHostToDevice
); // Transfer train memory
if( err != cudaSuccess){
printf( "%s in %s at above line %d\n",
cudaGetErrorString( err ),
__FILE__,
__LINE__
);
exit( EXIT_FAILURE );
} // Check for cuda error
err = cudaMemcpy(
teach_dev,
teach_cpu,
sizeof(double) * z_num[l_num-1] * teach_num,
cudaMemcpyHostToDevice
); // Transfer teach memory
if( err != cudaSuccess){
printf( "%s in %s at above line %d\n",
cudaGetErrorString( err ),
__FILE__,
__LINE__
);
exit( EXIT_FAILURE );
} // Check for cuda error
// Copy to device
err = cudaMemcpy(
mem_dev,
mem_cpu,
size,
cudaMemcpyHostToDevice
); // Transfer work memory
if( err != cudaSuccess){
printf( "%s in %s at above line %d\n",
cudaGetErrorString( err ),
__FILE__,
__LINE__
);
exit( EXIT_FAILURE );
} // Check for cuda error
結合荷重の初期化¶
必要なデータをデバイス(GPU)側へ転送したので、バックプロパゲーションの処理の 準備をします。先述の「Back Propagation」の項の通り処理を行ってゆきますが、 結合荷重の初期化の説明をしていませんでした。乱数による初期化には、正規分布 を用いる方法など、色々試されていますが、今回は-1から1の間の一様乱数を用いま す。ここでは、cudaに用意されているcurand_uniform()を用いていますが、まず、 0から2までの乱数を発生させ、-1することで-1から1の乱数を求めます。求めた数値 はユニットの数で割ることで簡単な正規化を行い、そして、求めた値は各結合荷重w へセットします。
set_instance()関数は、「汎用GPUにおける結合荷重及び関連値の確保と保持」の最 後で説明していますが、線形化メモリへ格納してある各値を、構造体への再割当てを 行っています。
__synchreads()関数は、cudaの同期関数ですが、すべてのthreadsにおいて、この部 分までの処理が完了するのを待って、後のコードを実行します。
LIST 6. 結合荷重の初期化
__global__ void init_wb(
long trg_phase,
long uniti,
long unitj,
long l_num,
void *mem,
long seed
){
int tid;
// thread id
long i_cnt;
// counter of input side
long j_cnt;
// counter of output side
NEURON_T *n;
// neuron structure
long jphase;
// number of output phase
curandState s;
// for randomize function
tid = blockIdx.x;
if(tid > unitj - 1){
// check for enable threads
return;
}
// New neuron instance
set_instance( l_num, &mem );
// Sync
__syncthreads();
// generate random number
curand_init(seed, tid, 0, &s);
n = (NEURON_T *)mem;
// set calculate phases
jphase = trg_phase + 1;
// set thread id
j_cnt = tid;
// i side loop
for( i_cnt = 0; i_cnt < uniti; i_cnt++ ){
// set randomize number
n->w[jphase][i_cnt + (uniti * j_cnt)]
= (double)((curand_uniform(&s)*2)-1)
/ (double)uniti;
}
// normal return
return;
LIST 7. デバイス(GPU)側による初期化関数の呼出し
// Set unit number i, j and k
uniti = z_num[0];
unitj = z_num[1];
// Calling initialize function
for( cnt = 0; cnt < l_num-1; cnt++ ){
// Set unit number i,j
uniti = z_num[cnt + 0];
unitj = z_num[cnt + 1];
init_wb<<<BLOCKS,1>>>(
cnt,
uniti,
unitj,
l_num,
mem_dev,
(long)time(NULL)
);
}
Neural Networkは、すべての層を同時に計算することはできません。それは、 現在の層を計算するのに、前あるいは後ろの層の計算結果が必要となるため です。そこで今回は、層内の神経細胞ユニットの並列化を行っています。つ まり、現在計算している層内のユニットを同時に計算しています。cudaから デバイス(GPU)側関数を呼び出す際に指定するBLOCKSとTHREADSは、処理する データのサイズに合わせて、適ほど指定します。
訓練(train)と推論(inference)¶
ここで、冒頭に説明した図1.訓練(train)と推論(inference)の処理を行います。 外側のループは、ForwardpropagationとBackpropagationの繰り返しループ、 つまり、訓練ループです。今回は何度か試した結果、3000回ほどに設定してい ます。また、data_curは、訓練に使っているデータのカーソルを示しています が、今回の排他的論理和(XOR)は、2[入力]×4[状態]であるため、4回ごとにリセ ットしています。そして、そのループの中には、
- calc_forward()
- calc_delta_at_out()
- calc_delta()
- calc_delta_w()
があり、calc_forward()は入力層から出力層に向かって順伝搬ループ、 calc_delta_at_out()は出力層分の一回実行され、calc_delta()とcalc_delta_w() は、出力層側(しかし出力層を除く)から入力層に向かって逆伝搬ループを行います。 最後に、デバイス(GPU)側から作業用メモリを転送して、終了です。
LIST 8. 訓練(train)
long data_cur = 0;
for(int loop_cnt = 0; loop_cnt < 3000; loop_cnt++, data_cur++ ){
if( data_cur == 4 ){
data_cur = 0;
}
// Call forward function
for( cnt = 0; cnt < l_num-1; cnt++ ){
calc_forward<<<BLOCKS,1>>>(
loop_cnt,
cnt,
mem_dev,
(double *)train_dev,
data_cur,
debug
);
}
// Call delta function for output
calc_delta_at_out<<<BLOCKS,1>>>(
1,
mem_dev,
(double *)teach_dev,
data_cur
);
// Call delta function
for( cnt = l_num-2; cnt >= 0; cnt-- ){
calc_delta<<<BLOCKS,1>>>(
cnt,
mem_dev
);
}
// Call delta function for w
for( cnt = l_num-2; cnt >= 0; cnt-- ){
calc_delta_w<<<BLOCKS,1>>>(
cnt,
mem_dev
);
}
}
err = cudaMemcpy(
mem_cpu,
mem_dev,
1,//size,
cudaMemcpyDeviceToHost
);
if( err != cudaSuccess){
printf( "%s in %s at above line %d\n",
cudaGetErrorString( err ),
__FILE__,
__LINE__
);
exit( EXIT_FAILURE );
}
今回は、calc_forward()の中にprintf()を組み込み、出力層のzを出力することで、 推論(inference)におけるForwardpropagationの結果を得ています。